
Local LLM-assisted text completion for Qt Creator
-
I ported the ggml-org/llama.vim: Vim plugin for LLM-assisted code/text completion vim script to a Qt Creator plugin at cristianadam/llama.qtcreator: Local LLM-assisted text completion for Qt Creator.
This is just like the Copilot plugin, but running locally using llama-server with a FIM (fill in the middle) model.
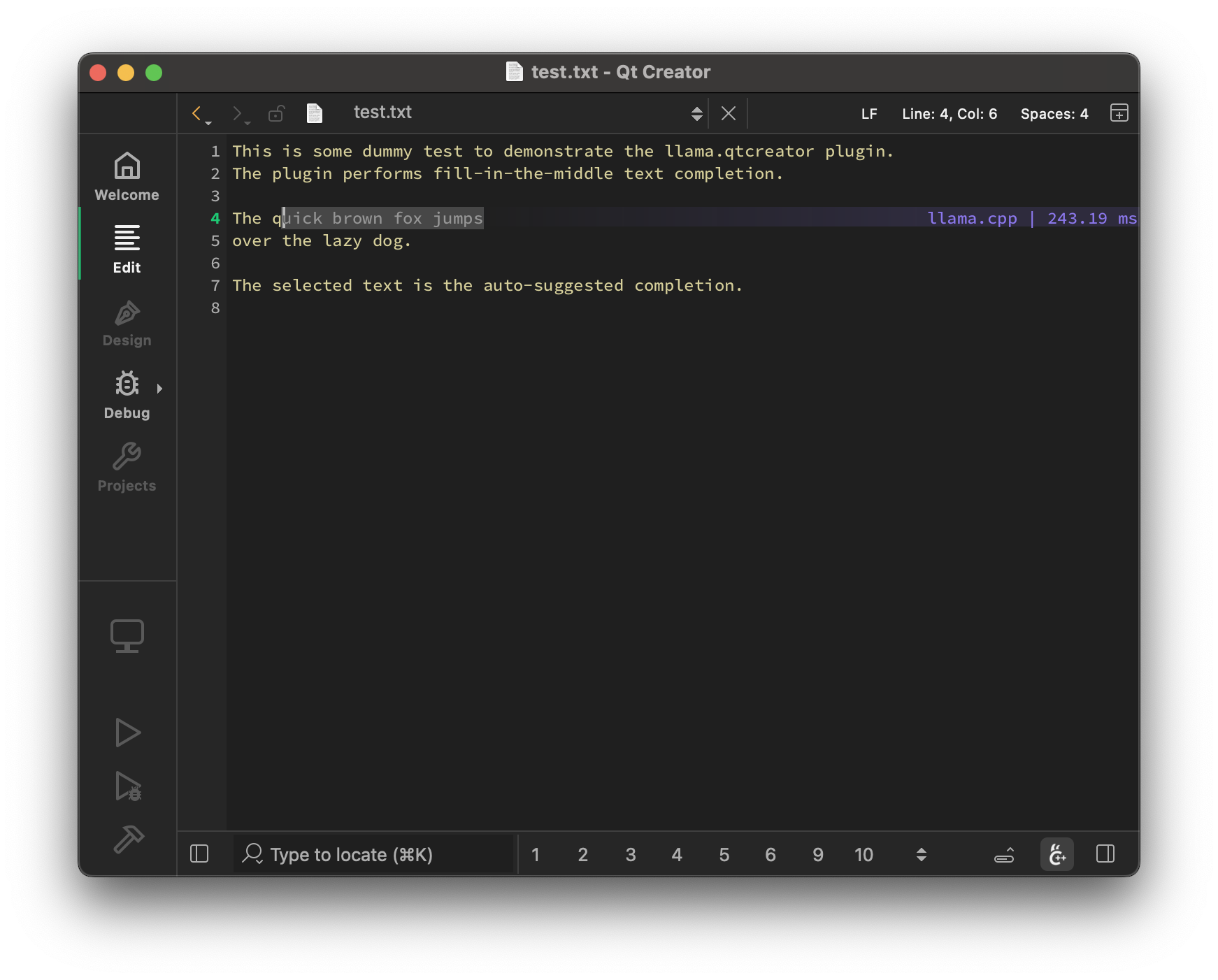
-
C cristian-adam marked this topic as a regular topic on
-
I've documented the experience at https://cristianadam.eu/20250817/from-llama-dot-vim-to-qt-creator-using-ai/
So if somebody wants to port any plugin from https://vimawesome.com/ they could do it using ... AI! 😅
-
-
First peak at the Chat functionality in #llama.qtcreator.
I used it to talk to gpt-oss 20b to create me a qt c++ chat widgets application that chats with a llama.cpp server using its json api.
See how it went at ... https://youtu.be/qWrzcx6QhOA
-
𝚕𝚕𝚊𝚖𝚊.𝚚𝚝𝚌𝚛𝚎𝚊𝚝𝚘𝚛 has now drag & drop support.
This means you can upload source files to the model! 🎉
Or you can upload a. image to a multi-modal model and ask for a mockup application for example.
Here is one example with 𝙳𝚎𝚟𝚜𝚝𝚛𝚊𝚕-𝚂𝚖𝚊𝚕𝚕-𝟸𝟻𝟶𝟽
-
I've released 𝚕𝚕𝚊𝚖𝚊.𝚚𝚝𝚌𝚛𝚎𝚊𝚝𝚘𝚛 v2.0.0 🎉
You can chat with a local AI from Qt Creator now!
You can install it by adding
https://github.com/cristianadam/qtcreator-extension-registry/archive/refs/heads/main.tar.gzto Extensions > Repository URLs
I've wrote about the experience at https://cristianadam.eu/20251005/from-react-to-qt-widgets-using-ai/
-
Great addition to QtCreator.
Unfortunately, for me the prompt does not generate anything. I downloaded the windows-x64 library and installed it via Extensions.
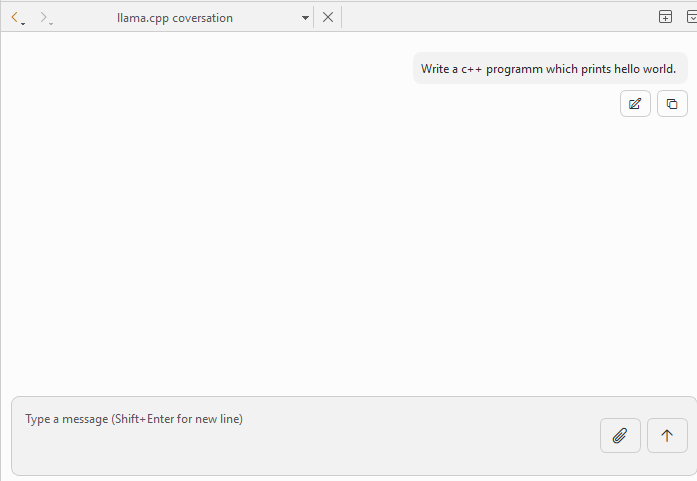
Edit:
After adding the Extension via Url there is no option to use it. "Tools" has no option to start the conversation. -
Great addition to QtCreator.
Unfortunately, for me the prompt does not generate anything. I downloaded the windows-x64 library and installed it via Extensions.
Edit:
After adding the Extension via Url there is no option to use it. "Tools" has no option to start the conversation.@Redman do you have
llama-serverrunning in background? This is just a client.On Windows is as easy as:
$ winget install llama.cpp $ llama-server -hf ggml-org/gpt-oss-20b-GGUF -c 0 -fa onThis assumes that your computer has at least 16 GB of VRAM.
If you have less, you could try with:
$ llama-server -hf ggml-org/Qwen2.5-Coder-3B-Instruct-Q8_0-GGUF -c 0I've seen this working on a computer with a NVidia Graphics Card having 6GB of VRAM.