
An interesting technical article
-
I happenstanced across https://thesmithfam.org/blog/2011/02/12/when-faster-is-actually-slower/.
A read for you algorithmers. I found it interesting [including the comments at the end] (and the blog is well written/presented) :)
-
Hi,
Interesting article indeed !
There's also this benchmark from Woboq that is more recent.
One thing to take into account though, there's a new implementation in the works for Qt 6.
Interested in AI ? www.idiap.ch
Please read the Qt Code of Conduct - https://forum.qt.io/topic/113070/qt-code-of-conduct -
Thanks for sharing!
Dave Smith's blog refers to the Qt docs' claim that QHash "provides significantly faster lookups" than QMap, but showed that for long QString keys, QHash is actually slower than QMap with his dataset.
First, it helps to better understand the meaning of Big-O notation. Big-O describes the what happens when the dataset size tends towards inifinity. QHash's complexity for look-up and insertion are both amortised O(1), which means that on average (ignoring rare expensive events like memory reallocation), the time to look-up/insert data in a tiny QHash is the same as an infinitely huge QHash. It makes no claim on the actual speed, and it doesn't really allow us to compare the speed of 2 containers with a particular dataset.
QHash's look-up complexity is amortized O(1) while QMap's look-up complexity is O(log n). So, we must understand this to mean that an infinitely huge QHash is significantly faster to look-up than an infinitely huge QMap. This doesn't knowledge doesn't tell us anything about a small QHash vs a small QMap. It also doesn't tell us where the crossover point is between "huge" and "small".
Woboq's blog that @SGaist linked to contains a good graph which shows the crossover occuring:
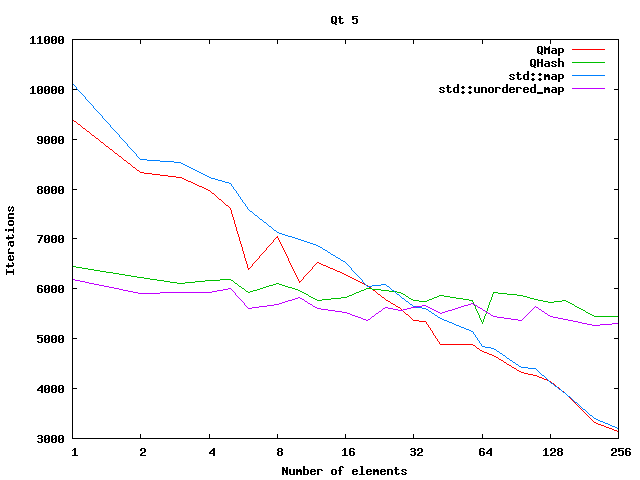
Depending on the types of keys used, the crossover point will shift, as David Smith has found.
Nice to see someone else is as interested-geeky as I am!
Geek is good. Geeks and nerds will rule the world one day
Here's a must-read for all geeks interested in the internal workings of Qt containers: https://marcmutz.wordpress.com/effective-qt/containers/
Qt Doc Search for browsers: forum.qt.io/topic/35616/web-browser-extension-for-improved-doc-searches
-
@JKSH
Thank you for further enlightenment.I have heard that geeky is attractive for young ladies these days, but haven't seen any empirical evidence at all for this in my case ;-)
One thing struck me in the first comment in the article:
But QHash will be faster on VERY huge data sets, because if you have
2^100 items or more (well, that should not be so often…) then QHash is faster again.I believe that
2 ^ 100is more than the number of atoms in the Universe --- it's good to know that if we want to locate a single atom we can look for it very quickly :) I'm wondering what datasets we use of this size? More to the point, how are we going to have a dataset/QHash/QMapfor this number of elements on a 64-bit machine? -
@JonB said in An interesting technical article:
I have heard that geeky is attractive for young ladies these days
Was at the bank. Teller asked me what my profession was. When I said I was a computer programmer she started asking more personal questions. I headed it off, but she is in her twenties and I am in my forties. Not sure what to think of that interaction.
-
@JonB said in An interesting technical article:
I believe that
2 ^ 100is more than the number of atoms in the Universe... I'm wondering what datasets we use of this size? More to the point, how are we going to have a dataset/QHash/QMapfor this number of elements on a 64-bit machine?We can't.
2^10032-bit integers requires5 x 10^18TB (or5 x 10^6yottabytes) of storage, at the very minimum. More if we use non-contiguous memory."Yotta-" is the largest SI prefix we currently have; there's no term to describe a multiplier bigger than that.
Qt Doc Search for browsers: forum.qt.io/topic/35616/web-browser-extension-for-improved-doc-searches
-
@fcarney said in An interesting technical article:
Not sure what to think of that interaction.
It could be an overly-friendly lass who simply needs a bit more professionalism/maturity when it comes to building rapport with customers.
It could be a case of a modern-day Beatlemania or Belieberism where rationality evaporates in the presence of a celebrity. (Programmer is the new Rock Star)
It could be a gold digger putting out feelers, as @JonB implied.
Whatever the case, it sounds like you handled the situation well!
-
2^10032-bit integers requires5 x 10^18TBYes, my point was I didn't think that poster's analysis could relate to a real, current situation. Nonetheless, I suppose his mathematical analysis about the behaviour would still hold.
You've also shed some light on something I didn't understand. You're saying
2^100is somewhere near10^18(I know that you're talking about different base units, so I ought to divide by a bit, but still...) Now, I thought my guess of2^100sounded a bit low for the supposed number of atoms in the Universe. I have a feeling that figure is something like10^76or some such. So10^nis a lot bigger than2^n, right? I thought inX^ythat the magnitude ofywas much more significant than the magnitude ofX? I know I could work it out, but how do you figure whatmis in10^m == 2^n?[Please don't tell me it's
m == n/5, that would be too obvious...? Hang on: since10 == 2^3.something, that meansm == n/3.something, so I divide/multiply the exponent by the3.somethingto convert between10^m == 2^n, is that it?!10^100 == 2^(300+something),2^100 =~ 10^30-ish?]It could be a gold digger putting out feelers, as @JonB implied.
Hang on, my reply was intended purely frivolously! I have no reason to imply that the person in question wasn't genuinely interested in the OP. Besides, gold-digging into programmer-geeks is probably not lucrative as we are underpaid & undervalues (speaking for myself) :)
Whatever the case, it sounds like you handled the situation well!
I'd have asked for her phone number ;-)
In the modern world perhaps we are not allowed to jest about these things, so we'd better stick to the question about exponents above....